De Cero a IA: El camino de la Ingeniería de Datos
Por Said Machado - CEO en Transmedia Lab
Desde el nacimiento de la computación moderna a finales de la década de 1940, de la mano de Alan Touring y Jhon Von Neuman, hemos experimentado un avance sin precedentes en el desarrollo de sistemas computacionales.
Fue Alan Turing, matemático ingles nacido en 1912 y fallecido a la temprana edad de 41 años, quien nos dejó el “gusanillo” de alcanzar la capacidad de razonamiento del ser humano con las, para entonces, nuevas computadoras y sus algoritmos de procesamiento de datos.
En su artículo "Computing Machinery and Intelligence" (Mind, octubre de 1950), Turing abordó el problema de la inteligencia artificial y propuso un experimento que se conocería como el test de Turing, un intento de definir un estándar para que una máquina pudiera ser considerada "inteligente".
La idea era, que se pudiera decir que una computadora "piensa" si un interrogador humano no podía distinguirla, a través de una conversación, de un ser humano.
En el artículo, Turing sugirió que, en lugar de desarrollar un programa para simular la mente de un adulto, sería mejor producir uno más simple para simular la mente de un niño y luego someterlo a un curso de educación.
Una forma inversa del test de Turing se usa ampliamente en Internet; el test CAPTCHA está destinado a determinar si el usuario es un humano o una computadora.
No fue hasta 1956, cuando un grupo de investigadores académicos, se reunieron en Dartmouth College y acuñaron la frase de Inteligencia Artificial, enmarcada en sus discusiones sobre lógica teórica la cual fue considerada como el primer programa de inteligencia artificial y usada para resolver problemas de búsqueda heurística.
Desde los años 60, se pensó que la IA tendría un desarrollo rápido y muy potente, capaz de alcanzar el potencial de un ser humano en tan solo 25 a 30 años. En realidad, lo que sucedió es que la capacidad de procesamiento estaba apenas en su fase de infancia temprana.
Apenas en 1951, teníamos el primer computador comercial UNIVAC I con capacidades tan impresionantes como una memoria de 12.000 bytes (12kB) y capaz de ejecutar 1000 transacciones por segundo. En contraste, los celulares de hoy día poseen una RAM 1 millón de veces más grade y capacidad de ejecutar Billones de operaciones por segundo.
Debido a esto y las fallas ante retos insalvables sin esa capacidad de cómputo, la IA entro en una fase de bajas inversiones e interés. El “invierno de la IA” llegó en la década de los años 70 y se extendió hasta finales de los años 80.
A finales de los años 80, la empresa Digital Equiment Corp desarrollo sistemas expertos para automatizar la configuración de sus mainframes VAX, lo cual demostró el potencial practico y comercial de la inteligencia artificial.
De allí, nació una incipiente revolución de sistemas expertos (software que utiliza una base de conocimientos de experiencia humana para tomar decisiones o resolver problemas en dominios específicos) que impulso los progresos de los algoritmos de aprendizaje de las maquinas (Machine Learning) y el desarrollo de las redes neurales, en particular los algoritmos de retropropagacion.
La conexión de esta revolución en la creación de software y algoritmos con el boom de crecimiento de datos, el internet y la llegada del Big Data (2006) junto a su modelo de software abierto, aceleró y potenció la expansión de la Inteligencia Artificial a los niveles en que hoy la conocemos y disfrutamos. Nivel que es comparado por los expertos con un bebe a inicios de sus primeros pasos.
Por otra parte, el concepto de Ingeniería de Datos nació alrededor de la década del 70 en el ámbito de conectar la planificación estratégica de negocios con los sistemas de información y tomo forma a partir del año 2000. Una vez más, el boom de crecimiento de datos, los servicios en la nube y la llegada del Big Data (2006) aceleró la apropiación del concepto por las grandes empresas de software. Compañías como Google, Facebook y Amazon se enfocaron en crear arquitecturas de Ingeniería de Datos que dieran respuestas a la variada demanda de cargas de trabajo y plataformas de Inteligencia Artificial IA.
Hoy, existen varias arquitecturas de Ingeniería de Datos relevantes al mundo de aprendizaje de maquinas e inteligencia artificial (ML/AI), entre las que podemos citar:
- Data Mesh es un marco arquitectónico diseñado para abordar los desafíos de administrar e integrar datos en organizaciones grandes y complejas. Sus principales características son la descentralización de la “propiedad” de los datos, orientación al autoservicio y gobernanza federada (existen políticas y estándares generales para garantizar la coherencia y el cumplimiento).
- Real Time Processing permite a las organizaciones tomar decisiones complejas al instante de ocurrir eventos que demanden una toma de decisiones oportunas.
- Cloud Native Solutions, diseñadas para dar respuesta a la evolución de los DataWarehouses estáticos y costosos hacia los nuevos DataLakehouses capaces de permitir analítica de ML/AI en tiempo real.
- AI-Driven Automation (Automatización impulsada por IA) que permite la creación de bots para la gestión preventiva y predictiva de los flujos de datos.
- Service-Oriented Architectures (SOA) para habilitar la integración de fuentes y servicios de datos
- Data Catalogs and APIs que facilitan el descubrimiento y la integración de datos sin inconvenientes, lo que hace que sea más fácil para los equipos acceder y utilizar datos en diferentes dominios.
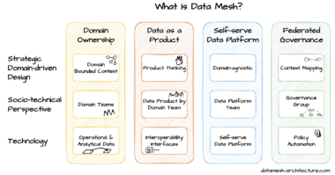
En el caso de Data Mesh (Malla de Datos), su núcleo está en la descomposición de sistemas complejos en piezas más pequeñas y manejables llamadas “dominios” los cuales tienen características como ser propiedad de un equipo de expertos, con autonomía de decisión sobre los datos y visión de colaboración con dominios relacionados. Esta estructura de dominios, promueve el agilismo como prácticas de desarrollo de software y contribuye a dar a la IA una velocidad de maduración creciente.
RTP y Cloud Native solutions van de la mano, nacidas en el crisol de la nueva analítica, las arquitecturas Kappa & Lambda para flujos de datos permiten el desarrollo del moderno concepto de DataLakeHouses con el consiguiente pase a retiro de los costosos y rígidos warehouses corporativos.
Estas se unen a los catálogos de Datos y Metadatos (AWS Glue, MetaStore, etc) junto con herramientas de gestión de APIs e ingestores de tiempo real (Apache Kafka) para alcanzar un estado, nunca antes logrado, de integración, colaboración, disponibilidad y velocidad de búsqueda de datos en entornos de cualquier volumen de datos.
La IA se ve beneficiada por estos avances y su aporte a las decisiones estratégicas de negocios se ve potenciada debido a la riqueza de la calidad de los datos en el lakehouse, alimentados a través de gestores de APIs desde aplicaciones transaccionales diversas e incluso de fuentes externas de datos que son objeto de técnicas de descubrimiento (data discovery) en tiempo real.
Esto permite clasificación, procesamiento y enriquecimiento de los distintos segmentos de datos (Apache Spark & Flink en combinación con Apche Hudi/Iceberg) que llegan a la empresa y la utilización de cada segmento en el entrenamiento de los modelos de ML/IA de acuerdo a cada aplicación que se deba alimentar.
En una próxima entrega estaremos conversando sobre los detalles de la arquitectura de DataLakeHouses y su empleo en la creación de modelos de IA!.

La IA: El Co-Piloto Invisible de SpaceX en la Carrera Espacial

El Aula Inteligente: Abrazando la IA en la Educación, Desde el Nido hasta la Universidad

El Lienzo Redefinido: Cómo la Inteligencia Artificial Impulsa la Creatividad y el Diseño

Ciberseguridad en Tiempos de la IA: Un Nuevo Paradigma de Protección

El Nuevo Código: El Impacto Transformador de la IA en el Desarrollo de Software

El Futuro de la IA: Oportunidades y Desafíos
Descubre aún más